
全球半导体这盘大棋,在加州圣塔克拉拉市彻底掀了桌。
当地时间4月22日,台积电甩出了一份密集到令人窒息的2026年度北美技术论坛更新内容,不仅公布了惊人且激进的先进制程时间表,更以前所未有的速度直逼物理极限。在对手还在为良率焦虑时,台积电已确立了从“电”到“光”的绝对统治力。
这场被业界视为“埃米战争”的技术竞赛,有玩家已然落后了一整个身位。
2029,台积电的双重“埃米”冲击波
台积电此次发布的战略核心,在于锁定了 2029年 这一关键时间点。
继2025年推出A14工艺后,台积电在论坛上直接打出了“A13”这张牌。根据资料显示,相较于前代,A13通过直接光学微缩,在保持设计规则与A14完全向后兼容的前提下,实现了6%的面积缩减,并通过DTCO带来了更优的功耗表现。相比隔壁三星、英特尔还在焦头烂额地攻克新节点,台积电的客户可以在A14/13之间无缝切换,直接省下天价的重新流片成本。
更让人震惊的是,台积电还预告了后续的 A12工艺,这将是A14的强化版。A12将引入“超级电轨”SPR背部供电技术,极大优化电流传输效率,为AI和HPC注入更强的动力,同样计划于2029年投产。此外,针对主流市场,台积电还公布了N2平台新成员N2U,预计2028年量产,相比N2P速度提升3%至4%,成为AI市场的均衡首选。
值得注意的是,台积电的规划远不止停留在2029年。同步在论坛上曝光的还包括预计2029年推出的40倍光罩尺寸SoW-X晶圆级系统,以及规划在2029年后进入量产的更先进节点,其技术纵深厚度已是竞品难以企及。
封装即平台:一场悄无声息的“集成革命”
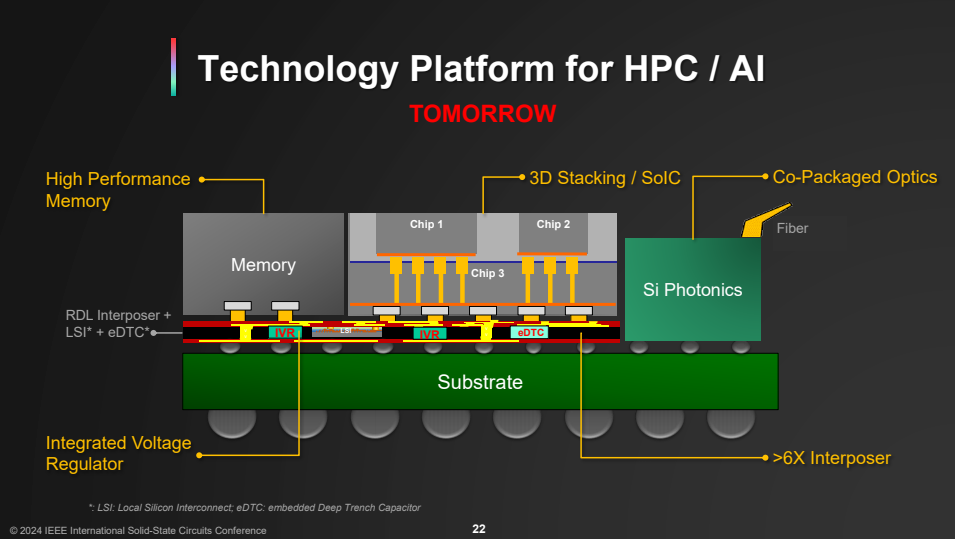
当不少人以为先进制程就是全部时,台积电用一道无情的“降维打击”告诉了全场:真正的战场,在封装。
这不仅仅是一场关于面积的游戏,而是下一代AI超级芯片的基础逻辑。为了满足AI对单一封装内内存和算力的贪婪,台积电正火力全开推进 3DFabric平台。目前,5.5倍光罩尺寸的CoWoS已实现量产,但为了容纳动辄十余颗计算芯粒与高达20个HBM的庞然大物,14倍光罩尺寸的CoWoS已经箭在弦上,预计2028年开始生产。
与此同时,台积电在3D硅堆叠方面也祭出了大杀器。规划2029年量产的A14对A14的SoIC 3D堆叠,其芯粒间I/O密度将是现款N2 SoIC的整整1.8倍。这意味着一阵翻倍的带宽洪流,将彻底铲除芯粒之间拖后腿的数据传输瓶颈。
光速互连:2026年,数据中心的速率革命
就在今年,台积电的一只脚已经踏上了颠覆现有数据中心架构之路。
台积电的紧凑型通用光子引擎COUPE即将投入量产。这是一款基于真正的CPO在基板上的解决方案。与传统的可插拔光模块不同,台积电将光子元件直接打入封装内部,带来的是直接翻倍的能效以及泼天般的降低90%的延迟。
这也意味着,阻碍AI集群扩展的“机架间长距离电信号损耗”这一老大难,终于迎来了物理层面的终局解法。
台积电董事长魏哲家在论坛上遥指这一蓝图,并表示台积电的先进制程在密度、效能和功耗方面持续引领业界,但寻找优化的脚步永不停止,只为确保客户在各种前瞻性设计到来时,拥有最可靠、最趁手的武器。
从埃米级别的原子操纵,到晶圆级别的系统集成,再到光子传输的未来解法,台积电在2026年北美技术论坛上掀开的这副底牌,清晰地勾勒出了一座超越传统代工厂范畴的“技术霸权”架构。当全球AI军备竞赛进入深水区,台积电正试图通过前所未有的系统级创新,站在价值链的最顶端,俯视一切。