
【导读:一场关于AI存储的“分层革命”】2026年2月26日,就在业界还在为高带宽内存(HBM)的下一代规格争得头破血流时,一场关于“后HBM时代”的隐秘战局被正式摆上台面。SK海力士——这位HBM市场的绝对王者,与刚刚独立不久的闪迪公司,在硅谷的心脏地带投下了一枚重磅炸弹:双方正式启动 “HBF规格标准化联盟” 。
这不仅仅是又一场技术发布会,这标志着全球存储产业正试图为即将到来的AI推理狂潮,构建一个全新的 “分层存储”秩序。当业界普遍预测HBM迟早会遭遇容量“天花板”时,HBF(高带宽闪存)正以一种“破局者”的姿态,试图填补AI计算中心最后一块存储拼图。一、 硅谷宣言:两大巨头的“合纵连横”当地时间2月25日,在位于美国加利福尼亚州米尔皮塔斯的闪迪公司总部,一场决定未来AI算力架构的会议悄然举行。SK海力士与闪迪联合召开了 “HBF规格标准化联盟启动会” ,正式宣告下一代存储器解决方案HBF的全球标准化战略进入实操阶段。
根据协议,双方已依托全球最大的开放性数据中心技术联盟——OCP(开放计算项目)框架,设立了专项工作组。这意味着HBF不再仅仅是两家公司的内部技术实验,而是旨在成为整个AI生态系统共同遵循的 “通用语言”。
“通过使HBF成为行业标准,我们将为整个AI生态系统的协同增长奠定基础。” SK海力士在声明中强调,此次合作是建立在双方技术互补性之上的深度绑定。一方握有HBM设计的“金钥匙”,另一方则拥有NAND闪存堆叠的“通行证”。
二、 HBF是什么?
不止是“NAND版的HBM”如果你将HBF简单地理解为“用NAND闪存做的HBM”,那可能会低估它的战略价值。
从技术架构上看,HBF确实借鉴了HBM的成功路径——它采用硅通孔(TSV)技术将多层NAND芯片垂直堆叠,并通过底部的逻辑芯片与GPU/CPU进行高速互联。但从产业定位上看,HBF瞄准的是一个全新的 “存储断层带”。
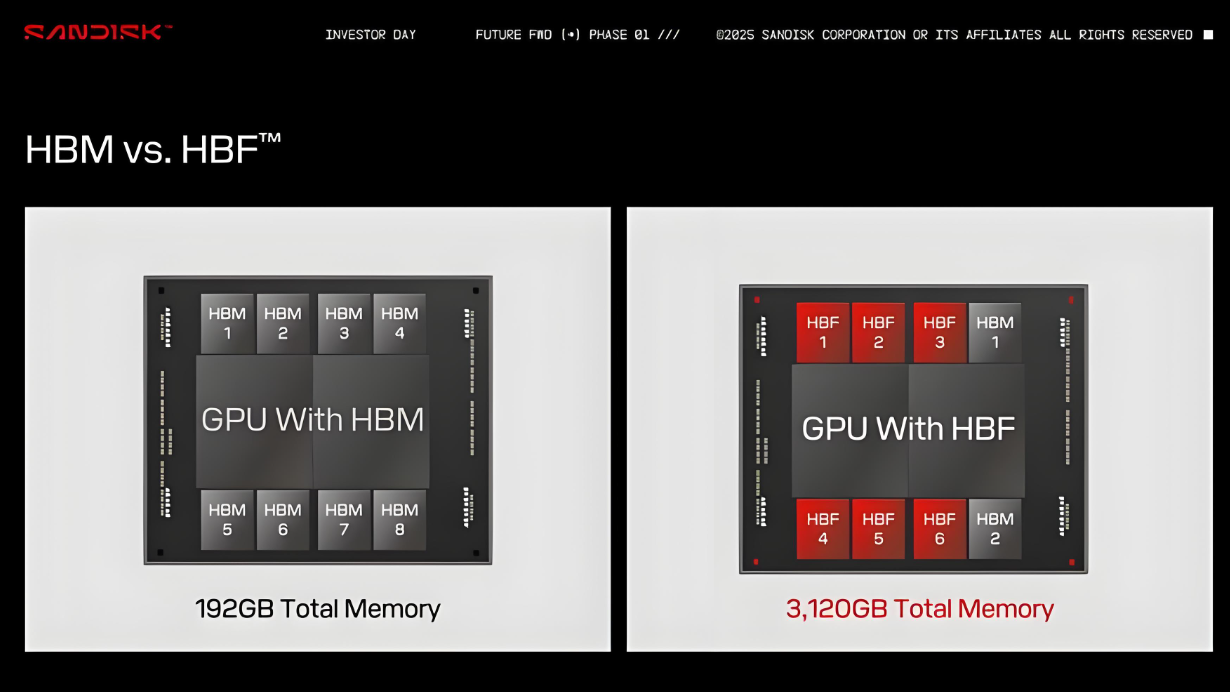
随着AI产业从“训练”迈入“推理”时代,行业正面临一个残酷的现实:GPU的算力越来越强,但“喂不饱”数据的情况越来越严重。HBM的痛苦: 带宽极高,但容量有限(单片通常几十GB),且价格昂贵。在大模型推理时,海量的权重数据和上下文(KV Cache)根本无法全部塞进HBM,导致GPU不得不频繁地访问外部存储,造成巨大的性能损耗和能源浪费。SSD的尴尬: 容量巨大,但延迟太高,带宽无法匹配GPU的吞吐需求。HBF正是横插在两者之间的“中间层”。
它提供了一种“黄金平衡”:容量碾压: 闪迪此前公布的数据显示,通过16层堆叠,单颗HBF容量可达512GB。这意味着在2.5D封装中集成8颗HBF,可为单颗GPU提供高达4TB的存储池,这相当于当前纯HBM方案的20倍以上,足以让拥有1.8万亿参数的GPT-4这类超大模型直接“驻留”在GPU旁边。
带宽匹配: 它采用与HBM相似的宽接口设计,虽然介质从DRAM换成了NAND,但带宽依然能达到与HBM相匹配的水平,彻底打破传统NAND的延迟壁垒
三、 为何是现在?
AI推理的“存力饥渴”SK海力士开发总管安炫社长在会议上点破了核心矛盾:“当前AI基础设施的竞争,已超越单一技术性能,核心在于整个生态系统的优化。”
随着ChatGPT类服务走向普及,数亿用户并发访问带来的推理负载,让“存力”变得比“算力”更棘手。数据吞吐的洪流: 推理不仅要处理用户的提问,还要实时调用庞大的知识库和上下文,这对存储系统的IOPS(每秒读写次数)和带宽提出了苛刻要求。能效比的焦虑: 数据中心耗电量惊人。HBF利用NAND的非易失性特性,无需像DRAM那样持续刷新数据,在提供海量存储的同时,能效表现极为出色,可显著降低数据中心的总拥有成本(TCO)。
业内专家形象地比喻:未来的AI存储就像一座智慧图书馆。SRAM是你手边的笔记本,HBM是你伸手可及的书架,而HBF则是你脚底下的庞大书库——容量巨大,但通过高速电梯(高带宽接口)随时可取 。
四、 路线图与野心:
2027年的“奇点”此次标准化启动,意味着HBF的商业化进程已按下快进键。
根据此前闪迪公布的战略规划,HBF的推进速度将远快于当年的HBM。2026年下半年: 预计交付首批HBF样品。
2027年初: 首款搭载HBF技术的AI推理设备样机有望面世。
2027年底至2028年: 被业界称为“HBM之父”的韩国科学技术院教授Kim Joungho预测,HBF届时将被集成至英伟达、AMD及谷歌等主流AI加速卡中。
更惊人的是长期预测: Kim Joungho教授认为,得益于NAND的容量优势和成熟的堆叠工艺,HBF的市场规模有望在2038年前后超越HBM,成为AI存储架构中占比最大的组成部分。而作为关键组件的整合型存储器解决方案,其需求将在2030年前后迎来全面扩张。
五、 前景预期与展望站
在2026年的当下回望,HBF的出现绝非偶然,它是AI算力需求“变态级”增长下的必然产物。
1. 短期预期(2026-2028):标准之争与生态构建
随着OCP工作组的成立,HBF将进入激烈的“标准定义期”。SK海力士与闪迪的先发优势明显,但三星、铠侠等巨头绝不会坐视不管。未来两年,我们将看到各大阵营围绕HBF的接口协议、物理尺寸、互联标准展开激烈博弈。谁能拿下英伟达、AMD等核心计算伙伴的背书,谁就能在下一轮AI硬件周期中占据主导。
2. 中期展望(2028-2032):从“数据中心”走向“边缘”,重构AI算力成本
一旦HBF进入量产,它将彻底改变AI服务器的硬件配置逻辑。未来的AI服务器将不再是“HBM独大”,而是形成 “HBM(缓存)+ HBF(主存)+ SSD(冷存)” 的三级存储架构。这将极大降低大模型推理的硬件门槛——企业无需堆砌昂贵的HBM,而是通过大容量HBF即可让更多用户并发运行更大模型。预计到2030年左右,随着HBF的普及,AI推理的单位Token成本将迎来断崖式下跌,真正引爆AI应用的全民化。
3. 长期愿景(2032以后):终结“内存墙”,开启存内计算时代
从长远看,HBF不仅是容量的补充,更是计算范式的变革者。当海量数据就近存储在GPU旁边且拥有极高带宽时,“存算一体” 将变得更加可行。未来,我们或许能看到部分计算任务直接下沉到HBF的逻辑层进行处理。HBF将作为撬动后摩尔时代AI算力持续增长的“新杠杆”,帮助人类逼近通用人工智能(AGI)的终极梦想。
结语:
SK海力士与闪迪的此次联手,不只是发布了一个新名词,而是在为AI的“下一个十年”打下地基。当算力狂奔,存力必须跟上。 HBF的全球标准化进程,正是整个IT产业为迎接智能爆炸时代所做的又一项关键准备。